
Bayesian Inference auf Deutsch 🇺🇸 ➔ 🇩🇪
This is my translation of Brandon Rohrer’s blog post (Nov 2, 2016) and utterly awesome explanation of Bayesian Inference.
https://www.youtube.com/watch?v=5NMxiOGL39M&feature=youtu.be
Bayesian Inference kann genutzt werden um genauere Vorhersagen über einen Datensatz zu erhalten. Die Technik ist besonders dann nützlich, wenn man nicht so viele Daten hast, wie man gerne hätte - deshalb will man so viel wie möglich an Vorhersagegenauigkeit aus ihnen herausquetschen.
Obwohl über Bayesian Inference manchmal mit viel Respekt gesprochen wird, ist sie weder Magie noch Mystik. Obwohl die Mathematik unter der Haube tatsächlich etwas verworren sein kann, sind die allgemeinen Konzepte absolut zugänglich. Kurzum, Bayesian Inference lässt uns genauere Schlussfolgerungen von unseren Daten ziehen, indem Wissen, dass wir über die Antwort bereits haben, mit eingebunden wird.
Bayesian Inference lässt sich auf die Ideen von Thomas Bayes, einem nonkonformistischem presbyterianischen Pfarrer, zurückführen, der vor ungefähr 300 Jahren in London lebte. Er schrieb zwei Bücher: eins zur Theologie, und eines zur Wahrscheinlichkeitsberechnung. Seine Arbeit enthielt das heute bekannte Bayes Theorem in seiner ursprünglichen Form, welches seitdem auf das Problem der Schlussfolgerung (Inference) angewandt wurde, dem technischen Begriff für eine wohlbegründete Vermutung. Die Popularität der Ideen von Bayes hat große Unterstützung von einem anderen Pfarrer, Richard Price, erhalten. Er sah ihre Bedeutung, entwickelte sie weiter und veröffentlichte sie. Es wäre daher historisch gesehen richtiger, Bayes Theorem die Bayes-Price Regel zu nennen.
Bayesian Inference im Kino

Stell dir vor, du bist im Kino und eine Person dort lässt ihr Ticket fallen. Du willst natürlich ihre Aufmerksamkeit. So sieht die Person von hinten aus (Foto oben). Man kann das Geschlecht nicht feststellen, nur dass die Person lange Haare hat. Ruft man nun “Entschuldigen Sie die Dame!” oder “Entschuldigen Sie der Herr!” Davon ausgehend was man über die Haarschnitte von Männern und Frauen in Deutschland (oder der Gegend, in der du wohnst) weiß, könnte man annehmen, dass dies eine Frau ist. (In dieser Vereinfachung gibt es nur zwei Haarlängen und Geschlechter.)
Jetzt stell dir eine Variation dieser Situation vor, in welcher die Person in der Schlange vor dem Männerklo steht. Mit dieser zusätzlichen Information würde man wahrscheinlich davon ausgehen, dass dies ein Mann ist. Die Benutzung von Common Sense und Welt/Hintergrundwissen ist etwas, das wir ohne großes Nachdenken tun. Bayesian Inference ist eine Methode dieses Vorgehen mit Mathematik einzufangen und dadurch genauere Vorhersagen zu treffen.

Um unserem Kinodilemma Zahlen zu geben, nimmt man an, dass ungefähr 50% Männer und 50% Frauen im Kino sind. Unter 100 Leuten, sind daher 50 Männer und 50 Frauen. Von den Frauen haben die Hälfte (25) lange Haare und die anderen 25 kurze Haare. Von den Männern haben 48 kurze Haare und 2 lange Haare. Da im Kino 25 Frauen und 2 Männer mit langen Haaren sind, liegt die Vermutung nahe, dass der Ticketbesitzer eine Frau ist.

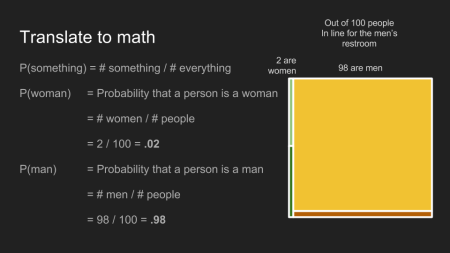
Von 100 Leuten in der Schlange zum Männerklo jedoch sind 98 Männer und zwei Frauen, die ihren Partnern das Warten versüßen. Die Hälfte der Frauen hat immer noch lange Haare, und die andere Hälfte hat kurze Haare, aber hier ist nur eine von jeder Haarlänge in der Schlange. Die Anteile der Männer mit langen und kurzen Haare sind die gleichen, aber da es nun 98 Männer sind, haben 94 kurze Haare und 4 lange. Da es jetzt eine Frau mit langen Haaren ist, aber vier Männer, liegt nun die Annahme nahe, dass es sich bei dem Ticketbesitzer um einen Mann handelt. Dies ist ein konkretes Beispiel des Prinzips dem Bayesian Inference folgt. Da man eine wichtige Information schon vorher hat - nämlich dass der Ticketbesitzer in der Schlange für das Männerklo steht - lässt uns genauere Vorhersagen über ihn/sie treffen.
Um genau über Bayesian Inference sprechen zu können, ist es wichtig unsere Ideen klar zu definieren. Leider brauchen wir dafür etwas Mathematik. Wir werden nicht zu tief einsteigen, aber haltet euch noch ein paar Absätze ran, und es wird sich auszahlen. Um die Grundlage zu legen, brauchen wir vier Begriffe: Wahrscheinlichkeit, bedingte Wahrscheinlichkeit (conditional probability), Verbundwahrscheinlichkeit (joint probability), und Randwahrscheinlichkeit (marginal probability).
Wahrscheinlichkeit
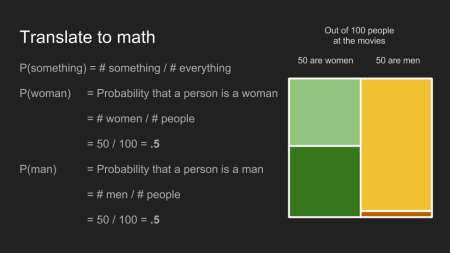
Die Wahrscheinlichkeit, das ein Event eintritt, ist die Anzahl der verschiedenen Möglichkeiten mit denen dieses Event passieren kann, geteilt durch die Gesamtanzahl von Events die passieren können. Die Wahrscheinlichkeit, das ein Kinogänger eine Frau ist, ist 50 Frauen geteilt durch 100 Kinogänger, .5 oder 50%. Das Gleiche gilt für Männer.
Bedingte Wahrscheinlichkeit (conditional probability)

Bedingte Wahrscheinlichkeiten beantworten die Frage “Wenn ich weiß, dass eine Person eine Frau ist, wie groß ist die Wahrscheinlichkeit, dass sie lange Haare hat?” Bedingte Wahrscheinlichkeiten werden genauso wie geradlinige Wahrscheinlichkeiten berechnet, nur dass sie eine Teilmenge (subset) aller Beispiele bestimmen, die die eine bestimmte Bedingung erfüllt. In unserem Fall, P(lange Haare | Frau), die bedingte Wahrscheinlichkeit, dass jemand lange Haare hat, in Anbetracht der Tatsache, dass die Person eine Frau ist, ist die Anzahl der Frauen mit langen Haaren geteilt durch die Anzahl aller Frauen. Dies beläuft sich auf .5 (50%), ob wir nun die Warteschlange betrachten, oder das Kino insgesamt.

Die selbe Mathematik angewandt, ist die bedingte Wahrscheinlichkeit, dass jemand lange Haare hat, in Anbetracht der Tatsache, dass die Person ein Mann ist, .04 (4%), ob er nun in der Schlange steht oder nicht.

Bei bedingten Wahrscheinlichkeiten gilt es sich zu merken, dass P(A | B) nicht das gleiche ist wie P(B | A). Zum Beispiel, P(süß | Welpe) ist nicht das gleiche wie P(Welpe | süß). Wenn das Ding, das ich halte ein Welpe ist, ist die Wahrscheinlichkeit, dass er süß ist sehr hoch. Wenn das Ding, das ich halte süß ist, dann ist die Wahrscheinlichkeit, dass es ein Welpe ist nur mittelmäßig-niedrig. Es könnte dann auch ein Kätzchen sein, ein Hase, ein Igel, oder ein kleiner Mensch.
Verbundwahrscheinlichkeit (joint probability)

Verbundwahrscheinlichkeiten sind nützlich um die Frage “Wie hoch ist die Wahrscheinlichkeit, dass jemand eine Frau mit kurzen Haaren ist?” Die Antwort darauf zu finden ist ein Prozess mit zwei Schritten. Zuerst schaut man sich die Wahrscheinlichkeit an, mit welcher jemand eine Frau ist, P(Frau). Dann binden wir die Wahrscheinlichkeit, dass jemand kurze Haare hat, unter der Annahme dass diese Person eine Frau ist mit ein, P(kurze Haare | Frau). Kombiniert geben uns die zwei Wahrscheinlichkeiten die Verbundwahrscheinlichkeit durch Multiplikation, P(Frau mit kurzen Haaren) = P(Frau) * P(kurze Haare| Frau). Wenn man diese Herangehensweise benutzt, kann man berechnen, was wir schon wussten - dass P(Frau mit langen Haaren) unter allen Kinogängern = .25, aber dass P(Frau mit langen Haaren) in der Warteschlange für das Männerklo = .01. Die Wahrscheinlichkeiten sind unterschiedlich, da P(Frau) in beiden Fällen unterschiedlich ist.

Gleichermaßen ist P(Mann mit langen Haaren) .02 unter allen Kinogängern, aber .04 in der Warteschlange zum Männerklo.

Im Gegensatz zu bedingten Wahrscheinlichkeiten, spielt die Reihenfolge bei Verbundwahrscheinlichkeiten keine Rolle. P(A und B) ist das Gleiche wie P(B und A). Die Wahrscheinlichkeit, dass ich Milch trinke und einen Gelee-donut esse ist die gleiche Wahrscheinlichkeit, dass ich einen Gelee-donut esse und Milch trinke.
Randwahrscheinlichkeit (marginal probability)
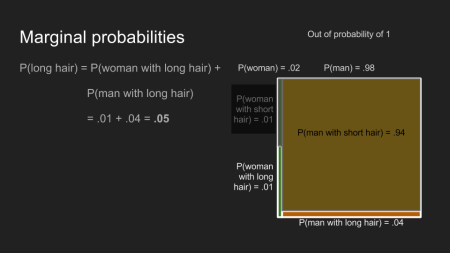
Der letzte Halt auf unserer Tour durch die Grundlagen sind Randwahrscheinlichkeiten. Sie sind nützlich, um die Frage “Wie hoch ist die Wahrscheinlichkeit, dass jemand lange Haare hat?” zu beantworten. Um diese Frage zu beantworten, müssen wir die Wahrscheinlichkeiten für die verschiedenen Möglichkeiten mit denen jemand lange Haare hat addieren - die Wahrscheinlichkeit ein Mann mit langen Haaren zu sein plus die Wahrscheinlichkeit eine Frau mit langen Haaren zu sein. Für die Kinobesucher bekommen wir zwei Randwahrscheinlichkeiten, P(lange Haare): .27 für alle Kinobesucher, aber .05 in der Warteschlange zum Männerklo.
Bayes’ Theorem
Nach den Grundlagen kommen wir nun zu dem Teil, der uns wirklich interessiert. Wir wollen die Frage “Wenn wir wissen, dass jemand lange Haare hat, wie hoch ist die Wahrscheinlichkeit, dass diese Person eine Frau (oder ein Mann) ist?” beantworten. Dies ist eine bedingte Wahrscheinlichkeit, P(Mann | lange Haare), aber die umgekehrte Version zu der Wahrscheinlichkeit, die wir bereits wissen, P(lange Haare | Mann). Da bedingte Wahrscheinlichkeiten nicht umkehrbar sind, können wir (noch) nichts über die neue bedingte Wahrscheinlichkeit sagen.
Glücklicherweise hat Thomas Bayes etwas cooles entdeckt das uns helfen kann.

Erinnern wir uns daran wie wir Verbundwahrscheinlichkeiten berechnet haben. Wir können Gleichungen schreiben für P(Mann mit langen Haaren) und P(lange Haare und Mann). Da Verbundwahrscheinlichkeiten umkehrbar sind, sind beide Wahrscheinlichkeiten gleich.

Mit ein bisschen Algebra, können wir nach dem Gesuchten auflösen, P(Mann | lange Haare).

Mit A und B ausgedrückt (anstelle von “Mann” und “lange Haare”) bekommen wir Bayes Theorem.

Jetzt können wir endlich zurück gehen und unser Kinoticket Dilemma lösen. Wir haben Bayes Theorem auf unser Problem angewandt.

Zuerst müssen wir unsere Randwahrscheinlichkeit erweitern, P(lange Haare).

Dann können wir unsere Zahlen einfügen und die Wahrscheinlichkeit, dass jemand ein Mann ist, mit dem Wissen, dass diese Person lange Haare hat berechnen. Für die Kinogänger in der Warteschlange zum Männerklo, P(Mann | lange Haare) = .8. Das bestätigt unsere Intuition, dass die Person, die das Ticket fallen gelassen hat, wahrscheinlich ein Mann ist. Bayes Theorem hat unsere Intuition in dieser Situation eingefangen. Was noch wichtiger ist, ist die Tatsache, dass es unser Vorwissen, dass es weitaus mehr Männer als Frauen in der Warteschlange zum Männerklo gibt mit einbezogen hat. Unter Einbezug unseres Vorwissen hat es unsere Annahme in dieser Situation upgedated.
Wahrscheinlichkeitsverteilung (probability distributions)
Beispiele wie das Kino-dilemma eignen sich gut um den Ursprung von Bayesian Inference zu erklären und zu zeigen wie sie funktioniert. In Data Science Anwendungen jedoch, wird sie oft benutzt um Daten zu interpretieren. Indem bereits existierendes Vorwissen über das, was wir messen mit eingebunden wird, können genauere Schlussfolgerungen aus kleinen Datensatzes gezogen werden. Ich werde das im Detail zeigen, aber zuerst müssen wir uns auf einen weiteren kleinen Umweg begeben. Wir müssen klären, was wir mit “Wahrscheinlichkeitsverteilung(en)” meinen.
Man kann sich Wahrscheinlichkeit als eine Kanne Kaffee vorstellen, in der noch genau so viel Kaffee ist, um eine Tasse zu füllen. Wenn es nur eine Tasse zu füllen gibt, gibt es kein Problem, aber wenn es mehrere Tassen zu füllen gilt, muss man sich entscheiden, wie der Kaffee zwischen den Tassen aufgeteilt wire. Man kann den Kaffee aufteilen wie man möchte, so lange der ganze Kaffee auf die Tassen verteilt wird. Im Kino könnte eine Tasse die Frauen, eine weitere Tasse die Männer repräsentieren.

Oder wir könnten vier Tassen verwenden um die Verteilung aller Kombinationen aus Geschlecht und Haarlänge zu repräsentieren. In beiden Fällen ergibt die gesamte Kaffeemenge eine Tasse voll.
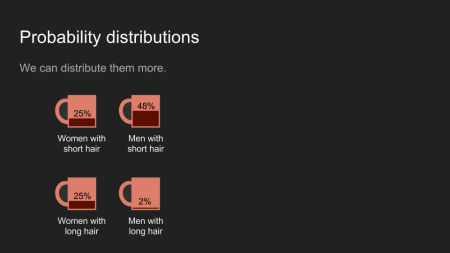
Für gewöhnlich stellen wir die Tassen beiseite und schauen uns die Menge in jeder Tasse als Histogram an. Es hilft sich den Kaffee als unseren Vermutung/Intuition vorzustellen, und die Verteilung zeigt wie stark wir vermuten, dass etwas der Fall ist.

Wenn man eine Münze wirft und das Ergebnis verdeckt, dann wird der Glaube genau gleich zwischen Kopf und Zahl verteilt sein.
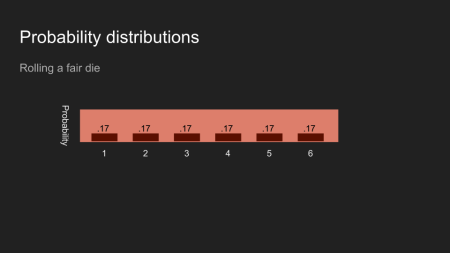
Wenn man einen Würfel rollt und das Ergebnis verdeckt, dann wird der Vorstellung über eine Zahl genau gleich zwischen den sechs Seiten des Würfels verteilt sein.
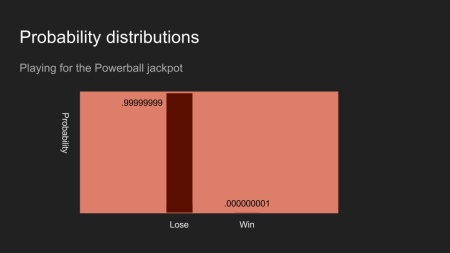
Wenn man ein Los kauft, dann wird der Glaube, dass es das Los ist das gewinnt gegen null gehen. Der Münzwurf, das Rollen des Würfels, und das Lotterieergebnis sind alle Beispiele für das Messen und Sammeln von Daten.
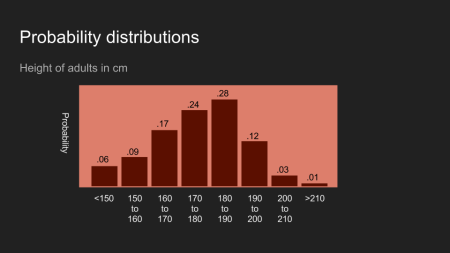
Es ist daher nicht überraschend, dass man auch über andere gesammelte Daten einen Vermutung oder eine Vorstellung hat. Stell dir die Größe von Erwachsenen in den USA vor. Wenn ich dir sage, dass ich jemand getroffen und die Größe der Person gemessen habe, könnte dein Glaube über die Größe der Person wie das Bild (Histogram) oben aussehen. Es zeigt den Glaube oder die Annahme, dass diese Person wahrscheinlich zwischen 150 und 200cm, und sehr wahrscheinlich zwischen 180 und 190cm groß ist.
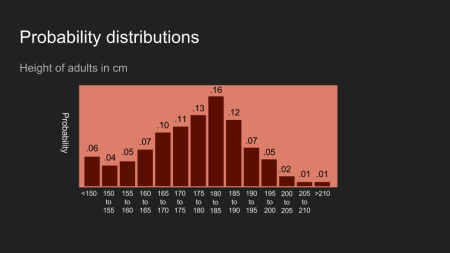
Verteilungen können in immer genauere/kleinere Behälter aufgeteilt werden. Stell dir vor, dass der Kaffee auf immer mehr Tassen verteilt wird um ein genaueres Bild unserer Vermutung zu erhalten.
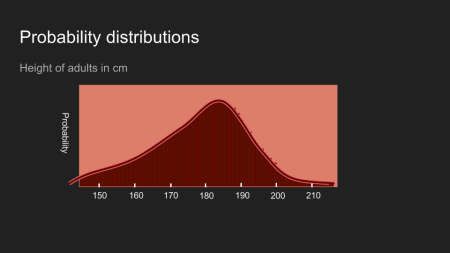
Am Ende steigt die Anzahl der imaginären Tassen so stark an, dass die Analogie zusammenbricht. Ab diesem Punkt, ist die Verteilung stetig (continuous). Die Mathematik mit der man dann arbeitet verändert sich ein bisschen, aber die grundlegende Idee ist immer noch hilfreich. Sie zeigt wie unsere Vermutung verteilt wird.
Danke für eure Geduld. Nachdem nun die Wahrscheinlichkeitsverteilung beschrieben ist, können wir Bayes Theorem benutzen um Daten zu interpretieren. Um zu zeigen wie das geht, wiegen wir meinen Hund.

Bayesian Inference beim Tierarzt
Der Name meines Hundes ist Reign of Terror (Herrschaft des Schreckens). Immer wenn wir zum Tierarzt gehen, dreht und windet sie sich auf der Waage. Nun ist es aber wichtig ein genaues Messergebnis zu bekommen, da ich, falls ihr Gewicht angestiegen ist, die Nahrungszufuhr minimieren muss. Sie liebt ihr Essen mehr als das Leben selbst, also steht viel auf dem Spiel.
Beim letzten Besuch haben wir drei Messungen geschafft bevor sie sich weigerte weiter auf der Waage zu bleiben: 19.3 lb (Pfund), 17.5 lb, und 14.1 lb. Es gibt hier ein statistisches Standardvorgehen. Wir können den Mittelwert, die Standardabweichung, und den Standardmessfehler für diese Zahlen berechnen und eine Verteilung für Reigns tatsächlichem Gewicht erstellen.

Diese Verteilung zeigt, was wir mit diesem Ansatz über ihr Gewicht zu wissen glauben. Es ist normal verteilt mit einem Mittelwert von 15.2 Pfund und einem Standardfehler von 1.2 Pfund. Die tatsächlichen Messwerte werden hier als weiße Linien gezeigt. Unglücklicherweise ist diese Kurve zu weit um zufriedenstellend zu sein. Obwohl die Spitze bei 15.2 Pfund liegt, zeigt die Wahrscheinlichkeitsverteilung, dass das Gewicht leicht so niedrig wie 13 Pfund und so hoch wie 17 Pfund sein könnte. Die Bandbreite ist viel zu groß um eine gut informierte Entscheidung zu treffen. Wenn wir auf solche Ergebnisse stoßen, werden für gewöhnlich mehr Daten gesammelt, aber in manchen Fällen ist dies nicht machbar oder zu teuer. In unserem Fall ist die Geduld von Reign zu Ende. Wir müssen uns mit den Ergebnissen, die wir bereits haben, zufrieden geben.
An dieser Stelle tritt Bayes Theorem ein. Es ist nützlich um das meiste aus einem kleinen Datensatz heraus zu holen. Bevor wir es anwenden, macht es Sinn nochmals die Gleichung und die verschiedenen Terme zu betrachten.
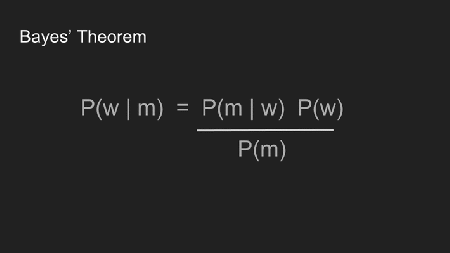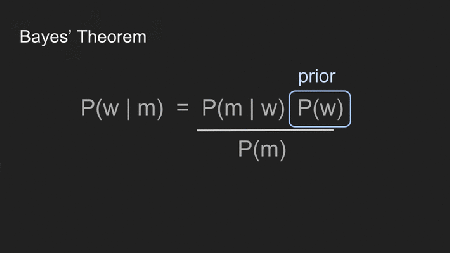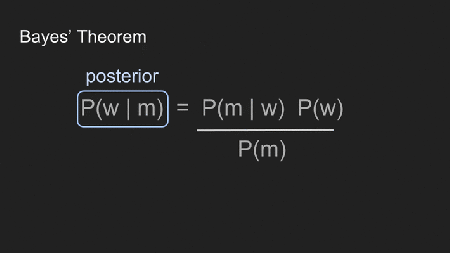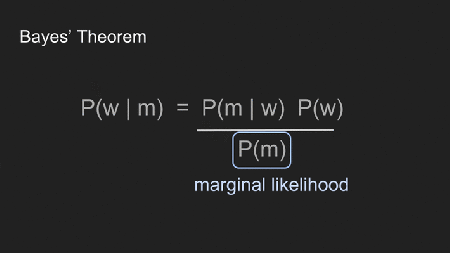
Wir fügen “w” (Gewicht) und “m” (Messergebnisse) für “A” und “B” ein um klarzumachen wie wir Bayes Theorem verwenden. Die vier Terme repräsentieren verschiedene Teile des Prozesses.
Der prior, P(w), zeigt unser vorherige Vermutung. In diesem Fall zeigt er was wir über Reigns Gewicht glauben zu wissen bevor wir sie auf die Waage setzen.
Die likelihood (Wahrscheinlichkeit), P(m | w) zeigt die Wahrscheinlichkeit, mit der unsere Messergebnisse für ein gewisses Gewicht auftreten. Man nennt sie auch die Likelihood der Daten.
Die posterior, P(w | m), zeigt die Wahrscheinlichkeit mit der Reign ein gewisses Gewicht hat, mit dem Wissen über die Messungen die wir gemacht haben. Das ist es, was uns am meisten interessiert.
Die Wahrscheinlichkeit der Daten, P(m), zeigt die Wahrscheinlichkeit, dass jeder Datenpunkt gemessen wird. Im Moment nehmen wir an, dass sie konstant ist und das die Skala unverzerrt ist.
Es ist keine schlechte Idee absolut skeptisch zu sein und keine Vermutungen über das Ergebnis anzustellen. In diesem Fall nehmen wir an, dass die Wahrscheinlichkeit dass Reigns Gewicht 13 Pfund, oder 15 Pfund, oder 1 Pfund oder 1000000 Pfund gleich ist und wir lassen dann die Daten zu uns sprechen. Um das zu tun nehmen wir einen uniform prior (gleichmäßiger prior) an. Das bedeutet, dass die Wahrscheinlichkeitsverteilung für alle Werte eine Konstante ist. Damit können wir Bayes Theorem zu P(w | m) = P(m | w) reduzieren.
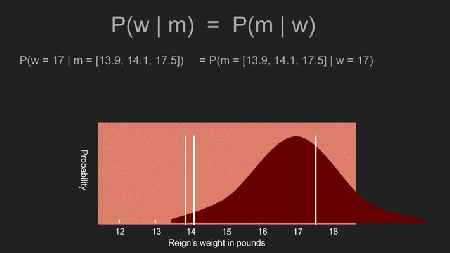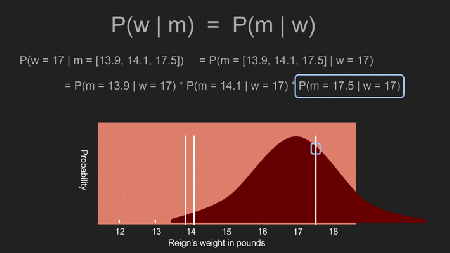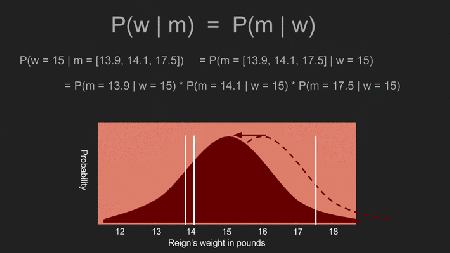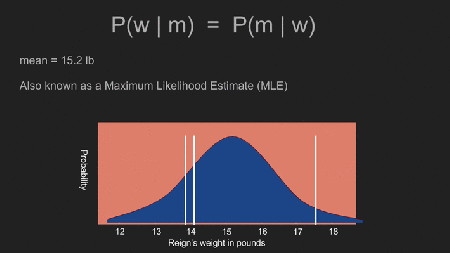
Nun können wir alle möglichen Werte für Reigns Gewicht verwenden und die Wahrscheinlichkeit berechnen, unsere drei Messergebnisse zu bekommen. Zum Beispiel: unsere Messergebnisse wären sehr unwahrscheinlich wenn Reigns Gewicht 1000 Pfund wäre. Sie wären aber sehr wahrscheinlich wenn ihr Gewicht tatsächlich 14 oder 16 Pfund wäre. Jetzt können wir durchgehen und, unter Verwendung von jedem hypothetischem Wert für ihr Gewicht, die Wahrscheinlichkeit berechnen, dass wir die Messergebnisse tatsächlich bekommen die wir haben. Das ist P(m | w). Da wir einen gleichmäßigen prior (uniform prior) verwenden ist es auch P(w | m), die posterior Verteilung (posterior distribution).
Es ist kein Zufall, dass dies der Antwort, die wir durch den Mittelwert, die Standardabweichung, und den Standardfehler, bekommen haben, sehr ähnlich sieht. Sie sind beide tatsächlich gleich. Wenn man einen uniform prior benutzt, bekommt man die traditionellen statistischen Schätzungen für das Ergebnis. Der Locus der Spitze der Kurve, der Mittelwert mit 15.2 Pfund wird auch Maximum Likelihood Estimate (MLE) für das Gewicht genannt.
Obwohl wir Bayes Theorem verwendet haben, sind wir einer nützlichen Schätzung noch nicht wirklich näher gekommen. Um sie bekommen muss unser prior ungleichmäßig (non-uniform) werden. Die vorher-Verteilung (prior distribution) repräsentiert unsere Vermutung über etwas bevor wir irgendwelche Messungen vorgenommen haben. Ein gleichmäßiger prior (uniform prior) zeigt, dass wir glauben, dass alle möglichen Ergebnisse gleich wahrscheinlich sind. Das ist fast nie der Fall. Wir wissen oft etwas über die Menge/Quantität die wir messen. Das Alter ist immer größer als Null. Temperaturen sind immer größer als ~ -276 Grad Celsius. Die Größe von Erwachsenen ist sehr selten größer als ~ 244cm (8 feet). Manchmal haben wir zusätzliches Wissen, dass manche Werte wahrscheinlicher auftreten als andere.
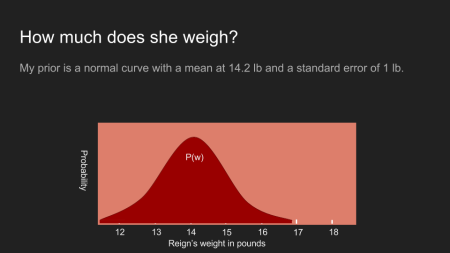
In Reigns Fall habe ich zusätzliche Informationen. I weiß, dass sie 14,2 Pfund gewogen hat, als sie das letzte Mal beim Tierarzt war. I weiß auch, dass sie sich nicht auffallend schwerer oder leichter anfühlt, auch wenn mein Arm keine besonders gute Waage ist. Deshalb glaube ich, dass sie um die 14,2 Pfund wiegt, vielleicht ein oder zwei Pfund mehr oder weniger. Um das zu zeigen, verwende ich eine Normalverteilung mit einem Peak bei 14.2 Pfund und einer Standardabweichung von einem halben Pfund.
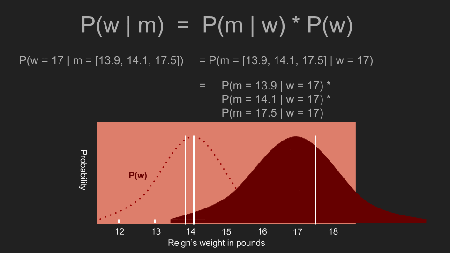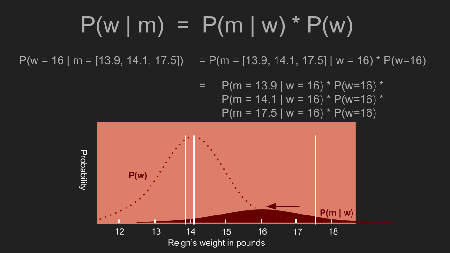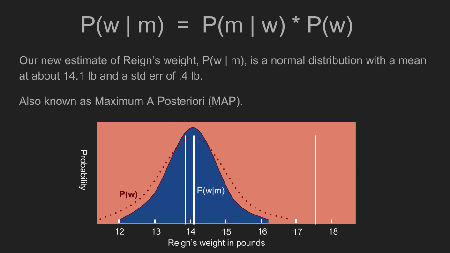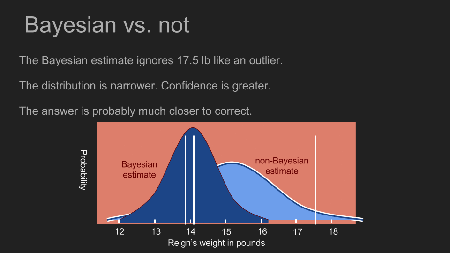
Da wir nun einen prior haben, können wir den Vorgang wiederholen in dem posterior distribution berechnet wird. Um das zu tun, ziehen wir die Möglichkeit in Betracht, dass Reigns Gewicht einen bestimmten Wert, sagen wir 17 Pfund hat. Dann multiplizieren wir die Wahrscheinlichkeit, dass sie tatsächlich 17 Pfund wiegt (entsprechend unserem prior) mit der bedingten Wahrscheinlichkeit, dass wir unsere Messergebnisse bekommen falls sie 17 Pfund wiegt. Dann wiederholen wir dies für alle möglichen Gewichte. Der Effekt des prior drückt manche Wahrscheinlichkeiten nach unten und verstärkt andere. In unserem Fall, bekommt die 13-15 Pfund Bandbreite mehr Gewicht, und weniger Gewicht auf Messergebnisse ausserhalb dieser Bandbreite. Im Unterschied zu dem uniform prior, welcher der Wahrscheinlichkeit das Reigns tatsächliches Gewicht 17 Pfund ist eine angemessene Möglichkeit gab, fällt 17 Pfund auf das Schwanzende der Verteilung mit einem non-uniform prior. Wenn man nun mit dieser Möglichkeit multipliziert geht die Wahrscheinlichkeit für das 17 Pfund Gewicht sehr weit nach unten.

In dem eine Wahrscheinlichkeit für jedes mögliche Gewicht berechnet wird, generieren wir eine neue posterior Wahrscheinlichkeit. Die Spitze dieser posterior distribution ist auch als maximum a posteriori estimate (MAP) bekannt; in unserem Fall 14.1 Pfund. Das ist ein bedeutender Unterschied zu dem Ergebnis, dass wir mit dem uniform prior berechnet haben. Die Spitze ist auch viel enger. Dies erlaubt uns eine weitaus zuversichtlichere Schätzung zu machen. Jetzt sehen wir, dass sich Reigns Gewicht nicht sehr verändert hat und ihre Portionen genau so groß bleiben können wie sie sind.
In dem wir das mit einbezogen haben, was wir über unser das was wir Messen schon gewusst haben, waren wir in der Lage eine genauere und zuversichtlichere Aussage zu treffen als anderswie. Es hat uns auch erlaubt Nutzen aus einem sehr kleinen Datensatz zu ziehen. Unser prior hat dem Gewicht von 17,5 Pfund eine sehr niedrige Wahrscheinlichkeit gegeben. Das ist fast das Gleiche, als wenn man das Messergebnis als Ausreißer ablehnt. Anstatt Ausreißer durch Intuition und Common Sense zu finden, erlaubt uns Bayes Theorem es anhand von Mathematik zu tun.
Als Randbemerkung ist zu sagen, dass wir angenommen haben das P(m) uniform war, aber hätten wir gewusst, dass unsere Skala auf irgendeine Weise verzerrt ist, hätten wir das in unsere P(m) mit einfiesen lassen können. Wenn die Skala nur gerade Zahlen hätte oder eine Messung von “2,0” 10% der Zeit ergibt, oder bei jedem dritten Versuch willkürliche Ergebnisse hätte, dann hätten wir unsere P(m) so gestalten können, das diese Sonderheiten darin wiedergegeben worden wären. Dadurch hätte sich die Genauigkeit von unserer posterior distribution verbessert.
Bayes-Fallen vermeiden
Obwohl das Wiegen von Reign die Vorteile von Bayesian Inference gezeigt hat, gibt es auch ein paar Fallen. Wir haben unsere Schätzung verbessert indem wir ein paar Vermutungen über die Antwort angestellt haben, aber der ganze Sinn etwas zu messes liegt darin etwas darüber zu lernen. Wenn wir vermuten, dass wir die Antwort bereits kennen, kann es sein, dass wir die Daten “zensieren.” Mark Twain hat die Gefahren von starken priors ganz kurz und bündig zusammengefasst. „Nicht das, was du nicht weißt, bringt dich in Schwierigkeiten, sondern das, was du sicher zu wissen glaubst, obwohl es gar nicht wahr ist.“
Wenn wir mit einer starken vorherigen Vermutung, dass Reigns Gewicht zwischen 13 und 15 Pfund liegt, dann wären wir nie in der Lage zu erfassen, ob ihr Gewicht nicht tatsächlich 12,5 Pfund ist. Unser prior würde diesem Ergebnis eine Nullwahrscheinlichkeit geben, und jede Messung die unter 13 Pfund liegt, würde ignoriert werden, ganz egal wie oft wir messen.
Glücklicherweise gibt es einen Weg unsere “Wette abzusichern” und es zu vermeiden blind Möglichkeiten zu eliminieren. Die Lösung ist jedem möglichen Ergebnis zumindest eine kleine Wahrscheinlichkeit zu geben. Sollte also Reign durch irgendeine physikalische Sonderheit tatsächlich 1000 Pfund wiegen, dann könnten unsere gesammelten Messergebnisse das in der posterior Wahrscheinlichkeit widerspiegeln. Dies ist ein Grund warum Normalverteilungen oft als prior verwendet werden. Sie konzentrieren den Großteil unserer Vermutung um eine kleine Bandbreite von Ergebnissen, aber sie haben lange Schweife (tails) die nie ganz Null werden ganz egal wie weit sie reichen.
